Series: BTC# – Learning to Program Bitcoin in C#
« Previous: Digital Signatures
Next: BTC#: Endianness »
Programming Bitcoin tackles verification first and signing second. I wrote my code in the opposite order because that’s what made sense to me.

New Zealand's Leading Amateur Geomythologist
Series: BTC# – Learning to Program Bitcoin in C#
« Previous: Digital Signatures
Next: BTC#: Endianness »
Programming Bitcoin tackles verification first and signing second. I wrote my code in the opposite order because that’s what made sense to me.
Series: BTC# – Learning to Program Bitcoin in C#
« Previous: The Bitcoin Curve
Next: Digital Signature Code »

Your digital identity is a private key, a secret number than only you know. It’s a bit like a PIN on your credit card but much, much longer. One of the major security flaws with credit cards is that you need to reveal your secret to authorise your spending.

Digital signatures prove that you know a secret without revealing the secret. Only a person in possession of the secret can produce a particular digital signature and the signature can’t be produced without knowing the secret. In other words, a signature authenticates a message and its origin can’t be denied.
A digital signature also incorporates details of the message that was signed, so the message can’t be tampered with without invalidating the signature.
A signature is built up from the signatory’s private key, a hash of the document being signed, and an ephemeral key that is used for a single message. Of these, only the document hash is publicly known. The other two are protected by an irreversible elliptic curve multiplication. The signature is made up of two components, r and s.
To verify that a signature is valid, the receiver needs the signature, the document hash, and the signatory’s public key. The signature’s r-component is derived from the ephemeral key and the s-component is composed in such a way that we can confirm that it was created using the document hash and the two secrets, without exposing either of the secrets.
The verification algorithm is an equation in which all the parts cancel out if the correct document hash and public key are provided. If the signature was created using a different private key than the one used to create the public key, the equation doesn’t balance, meaning the signature is not authentic. If the signature was created using a different document hash, the equation doesn’t balance, meaning that the document has been tampered with.

Programming Bitcoin provides a baffling analogical explanation of digital signature verification involving William Tell, inscriptions on arrow heads, and x-ray machines, which can be skipped, but do go through the equations and their derivations. If you want to go direct to the source, it’s NIST’s Digital Signature Standard.
« Previous: The Bitcoin Curve
Next: Digital Signature Code »
Series: BTC# – Learning to Program Bitcoin in C#
« Previous: BTC#: Elliptic Curves over Finite Fields
Next: BTC#: Digital Signatures »
The trick to breaking elliptic curve cryptography is reversing scalar multiplication of points on the curve. When we’ve got curves defined over small finite fields it’s easy: just work out the complete set of multiples (the members of the finite cyclic group) and look up the answer.
That’s why the prime used to define the finite field, and therefore the number of elements in the group, is mindbogglingly big.
The parameters of the secp256k1 curve used by Bitcoin are on the Bitoin Wiki.
I’ve copied those into a static Secp256k1 class. (There is a post on big integers in C# to jog your memory.)
public static class Secp256k1
{
// Highest order bit parsed as sign, so lead with 00.
public static BigInteger P { get; } = BigInteger.Parse("00FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFEFFFFFC2F", NumberStyles.AllowHexSpecifier);
public static BigInteger A = BigInteger.Zero;
public static BigInteger B = new BigInteger(7);
public static BigInteger Gx { get; } = BigInteger.Parse("0079BE667EF9DCBBAC55A06295CE870B07029BFCDB2DCE28D959F2815B16F81798", NumberStyles.AllowHexSpecifier);
public static BigInteger Gy { get; } = BigInteger.Parse("00483ADA7726A3C4655DA4FBFC0E1108A8FD17B448A68554199C47D08FFB10D4B8", NumberStyles.AllowHexSpecifier);
public static BigInteger N { get; } = BigInteger.Parse("00FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFEBAAEDCE6AF48A03BBFD25E8CD0364141", NumberStyles.AllowHexSpecifier);
}
I’ve also added a couple of extra constants to that class. These use the coefficients A and B and the prime P to create a curve object and the generator point coordinates Gx and Gy to create a generator point object.
public static EllipticCurveOverFiniteField Curve { get; } = new EllipticCurveOverFiniteField(A, B, P);
public static EllipticCurveFiniteFieldPoint G = Curve.GetPoint(Gx, Gy);
A couple of unit tests make sure that everything is defined properly.
[TestMethod]
public void Curve_GeneratorPointIsOnCurve()
{
Assert.IsTrue(Secp256k1.Curve.PointIsOnCurve(Secp256k1.Gx, Secp256k1.Gy));
}
[TestMethod]
public void GeneratorPointHasOrderN()
{
Assert.IsTrue((Secp256k1.N * Secp256k1.G).AtInfinity);
}
Note that the multiplication N x G, which checks the order of the generator point, would take vastly longer than the age of the universe to calculate by repeated addition but takes milliseconds when done by binary expansion.
This approach is slightly different to the one taken in the book, so compare them and use whichever you prefer.
« Previous: BTC#: Elliptic Curves over Finite Fields
Next: BTC#: Digital Signatures »
Series: BTC# – Learning to Program Bitcoin in C#
« Previous: Elliptic Curve Point Addition
Next: The Bitcoin Curve »
Coding for elliptic curves over finite fields is the target of our work so far. In Programming Bitcoin, Song just passes FieldElement objects into Point’s constructor and lets the Python interpreter’s type inference do the rest. The mathematical code in the Point class just calls the operator functions defined on FieldElement instead of the integer versions.
In the strictly typed world of C#, we don’t get that luxury. There’s no interface or other generic type constraint common to our FiniteFieldElement and Int32, so I’ve written a new class, EllipticCurveFiniteFieldPoint. (Get the repo.)
Series: BTC# – Learning to Program Bitcoin in C#
« Previous: BTC#: Elliptic Curves
Next: Elliptic Curves over Finite Fields »
The elliptic curve points we’ve modelled with the code in the previous post represent points (x, y) on the curve. Adding points together is going to form the basis of our elliptic curve cryptography maths. However, elliptic curve point addition is not a lot like the vector addition you’ve seen elsewhere. We don’t just add the xs and ys.
Elliptic curve point addition is an operation on two point that results in a third. However, it doesn’t work the way you might intuitively think. We don’t just add the xs and ys. There are various rules for point addition depending on the relationship of the two points to be added.
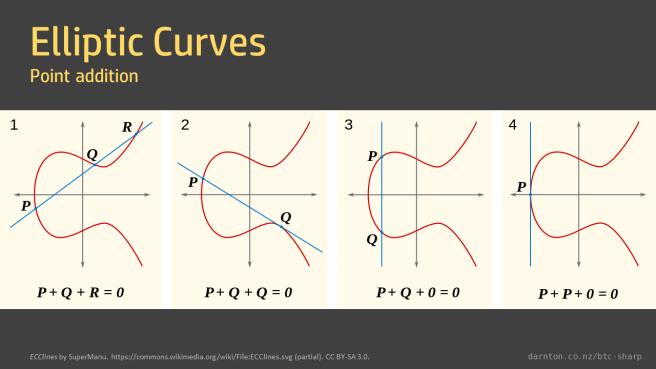
The meaning of each of these cases is covered in the book.
In the previous post where I created the EllipticCurvePoint class, I said that I’d made the y parameter nullable. This is to model the idea of “the point at infinity”. A vertical line intersecting the curve twice is regarded as also passing through the point at infinity.
public bool AtInfinity
{
get { return !Y.HasValue; }
}
The point at infinity act as the identity in point addition, meaning that any point plus the point at infinity results in itself
A + I = A
and that any point added to its inverse, i.e. any point minus itself, results in the point at infinity
A + (-A) = I
This gives us the first couple of cases to model for our addition operator.
public static EllipticCurvePoint operator +(EllipticCurvePoint p1, EllipticCurvePoint p2)
{
//At least one of the points is at infinity
//This is the identity operation for addition so return the other point.
if (p1.AtInfinity) return p2;
if (p2.AtInfinity) return p1;
//Same x, different y (or same y and tangent is vertical),
//meaning that the line is vertical.
//Return the point at infinity.
if ((p1.X == p2.X && p1.Y != p2.Y) || (p1 == p2 && p1.TangentIsVertical))
{
return new EllipticCurvePoint(p1.X, null, p1.A, p1.B);
}
//More code here later...
}
There are two situations left that we need to handle, the addition of two points with different xs, and the addition of a point to itself. In the first case we need to find the line between the two points and find where else it intersects the curve, as in graph 1 above. In the second case we need to find the tangent to the point and see where that line intersects the curve, as in graph 2.
The derivation of the formulae for finding the gradients of these lines and, from there, where they intersect with the curve is somewhat involved and covered in detail in the book.
It’s worth reading through the explanations in the book, because repeated point addition on the bitcoin elliptic curve will be used later, in the cryptography section, to generate signatures.
With the formulae derived we can implement the rest of the addition operator.
public static EllipticCurvePoint operator +(EllipticCurvePoint p1, EllipticCurvePoint p2)
{
//Previous code in here.
//Where p1 coincides with p2, find the slope of the tangent.
//Otherwise find the slope of the line between the points
var slope = (p1 == p2)
? p1.SlopeOfTangent
: (decimal)(p2.Y.Value - p1.Y.Value) / (p2.X - p1.X);
var x3 = slope * slope - p1.X - p2.X;
var y3 = slope * (p1.X - x3) - p1.Y.Value;
return new EllipticCurvePoint((int)x3, (int)y3, p1.A, p1.B);
}
There are tests to cover each scenario.
[TestMethod]
public void operatorAddition_twoPointsReturnTheThird()
{
var a = new EllipticCurvePoint(2, 5, 5, 7);
var b = new EllipticCurvePoint(-1, -1, 5, 7);
var c = new EllipticCurvePoint(3, -7, 5, 7);
Assert.AreEqual(c, a + b);
}
Of course, as good TDD practitioners, the tests were written first.
Next time, I’ll combine the FiniteFieldElement with the elliptic curve code.
« Previous: BTC#: Elliptic Curves
Series: BTC# – Learning to Program Bitcoin in C#
« Previous: Finite Fields in C#
Next: Elliptic Curve Point Addition »
Chapter Two starts with a recap of some high-school maths, looking at the graphs of linear equations, quadratics, and cubics. This is worth reviewing, depending on how amazing or otherwise your high school maths was.
There are many types of cubic curves beyond those we learned about in school. Elliptic curves are type of cubic curve that have the form
y2 = x3 + ax + b
Knowing this, we can fully define an elliptic curve with just the coefficients a and b.
For example, the elliptic curve used in bitcoin cryptography is called ‘secp256k1’, which is defined by the coefficients a = 0 and b = 7, giving
y2 = x3 + 7
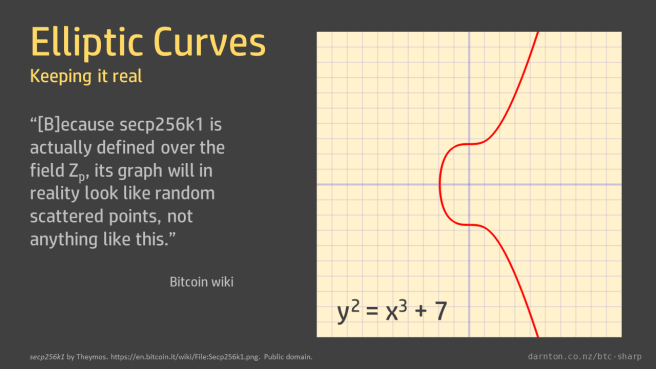
The graphs of elliptic curves that we often see show the curves over real numbers. The Bitcoin wiki shows such a graph and then notes “that because secp256k1 is actually defined over the field Zp, its graph will in reality look like random scattered points, not anything like this.”
The reason we have points instead of a line is that the curve is only defined for values in the field, where x and y are integer values. The reason the points are all over the place is because in finite space the curve wraps around. Like in Pacman, where running off the right-hand side of the screen wraps you around to the left-hand side.
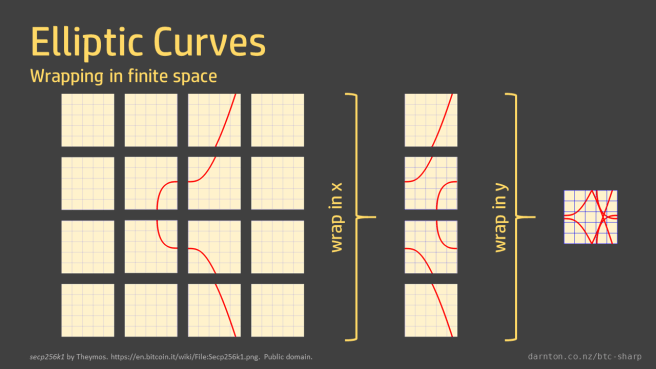
You can think of the graph as tiled, with tiles the size of the field order. Imagine the graph drawn on tiles of the appropriate size and then all the tiles overlaid on each other. You can see that the result is symmetrical around the middle of the y-axis but otherwise very hard to follow.
When we limit the values to the elements in the finite field we get the scatter of points described above. This is a graph of y2 = x3 – x in F61.
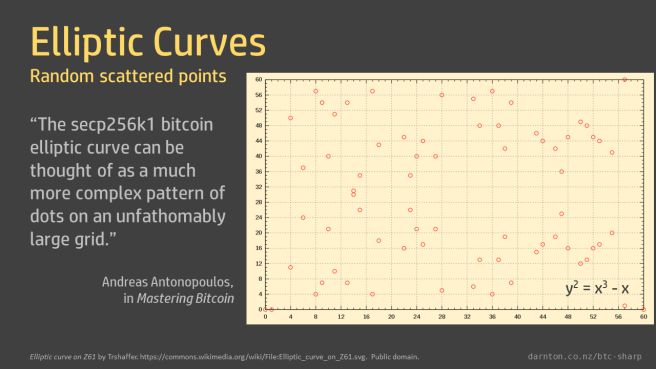
The field order for the bitcoin curve is vastly bigger than the 61 shown here, so its graph is, as described by Andreas Antonopoulos in Mastering Bitcoin, “a much more complex pattern of dots on an unfathomably large grid.”
I ended up doing two versions of the elliptic curve code. A version for the introductory code in this chapter, for getting to grips with elliptic curve point addition, and a second version that works with finite field elements that we look at in the next chapter. Song doesn’t do that in the book because Python’s dynamic type system makes it much easier to slide from one to another.
For this Chapter we’ll only worry about the simpler first case.
The first version (EllipticCurvePoint – see repo) takes integer parameters and implements equality and addition operators, as well as a method to check whether a point is on a given curve.
In the sample code, Song creates a Point class that takes both curve parameters (a, b) and point parameters (x, y) in its __init__ function and then raises an error if the point is not on the curve.
I’ve done something similar but extracted the PointIsOnCurve check as a separate method so it can be tested independently and used without raising exceptions.
public EllipticCurvePoint(int x, int? y, int a, int b)
{
if (y.HasValue && !PointIsOnCurve(x, y.Value, a, b))
{
throw new ArgumentException($"Point ({x}, {y}) is not on the curve y^2 = x^3 + {a}x + {b}.");
}
X = x;
Y = y;
A = a;
B = b;
}
I’ve made the y parameter nullable. Later on we’ll use this to represent “the point at infinity.” Needless to say this doesn’t come up in Python because any variable can be set to None.
public static bool PointIsOnCurve(int x, int y, int a, int b)
{
return (int)Math.Pow(y, 2) == (int)Math.Pow(x, 3) + a * x + b;
}
Note the integer casts here. The Math.Pow() method takes and returns double. There’s an implicit conversion for the inbound arguments but the result needs to be explicitly cast back to an int.
The equality operator is implemented in a very similar way to what I did for the FiniteFieldElement class, so there’s no need to go over that again.
In the next post, we’ll look at the addition operator and what it means to add points on an elliptic curve.
« Previous: Finite Fields in C#
Next: Elliptic Curve Point Addition »
Series: BTC# – Learning to Program Bitcoin in C#
« Previous: Big Integers in C#
Next: Elliptic Curves »
To understand Bitcoin transactions, you need to understand elliptic curve cryptography. To understand elliptic curve cryptography, you need to understand finite fields. Programming Bitcoin’s first chapter goes through the maths of finite fields and develops a Python implementation.
The maths of addition, subtraction, and multiplication of finite fields is essentially the maths of modular arithmetic. Division is less intuitive and it’s best to think of it simply as the inverse of multiplication. The book gives an extensive explanation, which I won’t repeat here, but I will give a hand-waving summary (mainly to help cement it in my own mind.)
Multiplication is simply standard multiplication mod the field order. For example in F5, 2 x 4 = 8 % 5 = 3.
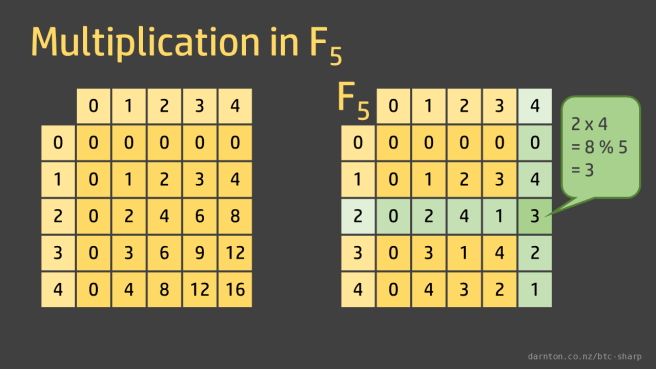
Division is simply the inverse operations, so 3 ÷ 2 = 4 and 3 ÷ 4 = 2.
A rigorous explanation of how to do finite field division, courtesy of Jimmy Song and Pierre de Fermat, is given in Programming Bitcoin.
Now we can see why finite fields must have a prime field order. Where we have a non-prime field order, division is not defined because the products are not unique. We can see the repetition in the rows and columns below.

In F6, 2 x 4 = 8 % 6 = 2. But 2 x 1 = 2 and 5 x 4 = 2 as well.
(2 x 4) ≡ (2 x 1) ≡ (5 x 4)
So 2 ÷ 2 and 2 ÷ 4 don’t have unique answers.
The book’s GitHub repo has all the Python source code; mine has the C# version that I’m developing as I work through the book.
The class developed to represent a finite field element has two properties: the value of the element and its field order (i.e. the number of elements in the field). As mentioned in the previous post, I implemented these properties as BigIntegers because I know what’s coming.
public BigInteger Value { get; }
public BigInteger Order { get; }

If you grab a copy of the code you can see that all the rest is implementations of various mathematical operators.
In Python, this is done by defining special operator functions, like __eq__. In C# this is done using overloadable operators.
The C# version of the equality operator looks like this:
public static bool operator ==(FiniteFieldElement a, FiniteFieldElement b)
{
return ((object)a == null && (object)b == null) || (object)a != null && a.Equals(b);
}
Note that in C# if the == operator is overloaded, the != operator needs to be as well. They both do similar work, which has been delegated to the Equals method:
public override bool Equals(object obj)
{
if ((obj == null) || !GetType().Equals(obj.GetType()))
{
return false;
}
else
{
FiniteFieldElement fe = (FiniteFieldElement)obj;
return (Value == fe.Value) && (Order == fe.Order);
}
}
This is a very common way of implementing this method: a null check and a type check and, if that’s all OK, checking that the two properties are the same.
When Equals() is overridden, GetHashCode() must also be overridden. For a simple class like this it’s easy and quick to take the hashes of the two properties and XOR them.
public override int GetHashCode()
{
return Value.GetHashCode() ^ Order.GetHashCode();
}
One little gotcha comes up if you ever want to test against null. You can see that in the null check in the operator, the value being tested is cast to an ‘object’ type. If you don’t do that the operator calls itself and eventually causes a stack overflow, so you need to call the base implementation to get the expected behaviour.
The addition, subtraction, multiplication, and division operators are all also overridden, the first three using simple modular arithmetic equivalents, and the divide operation using a result found in the book, derived from a definition of division as the inverse of multiplication.
In the operator definitions, note the use of the mod() method I talked about in a previous post to handle C#’s lack of a modulo operator, which could bite you when it comes to subtraction.
public static FiniteFieldElement operator -(FiniteFieldElement a, FiniteFieldElement b)
{
if (a.Order != b.Order)
{
throw new ArgumentException($"Subtraction operator is not defined for elements of different order ({a.Order} and {b.Order}.");
}
return new FiniteFieldElement((a.Value - b.Value).Mod(a.Order), a.Order);
}
In the book, there’s some discussion of how to reimplement exponentiation for finite fields. This is one thing that’s easier in C# because we can just use BigInteger’s built-in ModPow function.
public FiniteFieldElement Pow(BigInteger exp)
{
return new FiniteFieldElement(BigInteger.ModPow(Value, exp, Order), Order);
}
Mathematical libraries like this are the perfect place for textbook Test Driven Development. The functions are all nicely contained and there are no dependencies like user interfaces or databases that need to be stubbed out or worked around. It’s quick and easy to test first, write failing tests for every bug, and maintain good coverage.
To check that the remainder vs. modulus problem isn’t tripping us up, we can do this:
[TestMethod]
public void operatorSubtraction_modulo()
{
var a = new FiniteFieldElement(7, 13);
var b = new FiniteFieldElement(12, 13);
var c = new FiniteFieldElement(8, 13);
Assert.AreEqual(c, a - b);
}
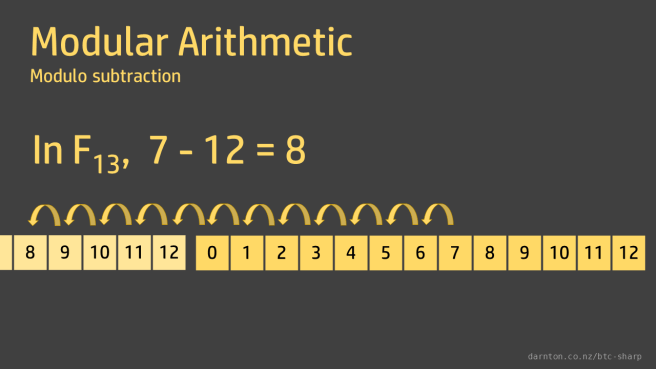
In F13, 7 – 12 = 8 and all is well.
« Previous: Big Integers in C#
Next: Elliptic Curves »

Series: BTC# – Learning to Program Bitcoin in C#
« Previous: Big Numbers Are Big
Next: Finite Fields in C# »
Programming Bitcoin means using some very big numbers. We talked about why in the previous post. In Python, which Programming Bitcoin uses for all its code, the way integers are implemented is hidden from the user. The sample code in the book starts off using small numbers to illustrate the ideas and then shifts seamlessly into using the huge numbers required by the cryptographic algorithms.
In Python you can say
>>> p = 19
and just as easily say
>>> p = 2**256 - 2**32 - 977
It all works as expected.
In C# if you try the equivalent
> var p = Math.Pow(2, 256) - Math.Pow(2, 32) - 977;
the result will be a floating point number and precision will be lost. The result doesn’t store all of the significant figures and so it’s inexact. You can see this if you compare the prime number we’ll be using for our cryptography, which is slightly lower than 2256, with 2256. Because the least significant figures have been thrown away, the two numbers are equal. This is no good for our purposes.
> Math.Pow(2, 256) - Math.Pow(2, 32) - 977 1.157920892373162E+77 > Math.Pow(2, 256) - Math.Pow(2, 32) - 977 == Math.Pow(2, 256) true
If we convert the results of the Math.Pow operations to integer types they will truncate (and flip the sign bit if we’re using signed types):
> (long)Math.Pow(2, 256) -9223372036854775808
To translate the examples into C# we need to know how to handle big integers. The standard integer type, Int32, is a 32-bit integer, with a maximum value of 2,147,483,647 (or 4,294,967,295 if you use unsigned integers). This is microscopic compared to the huge numbers we’ll be dealing with. Int64s don’t get us much closer.

The answer is the BigInteger struct, in the System.Numerics namespace.
We can create BigInteger objects in various ways. For small numbers they can be assigned from an int or a long:
public static BigInteger B = new BigInteger(7);
For bigger numbers, such as the cryptographic parameters we’ll be using, we can create a BigInteger from an array of bytes or parse a string.
We can specify a string of hexadecimal characters to be parsed. One thing to be aware of is that the highest order bit will be parsed as the sign, so lead with “00”.
public static BigInteger P { get; } = BigInteger.Parse("00FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFEFFFFFC2F", NumberStyles.AllowHexSpecifier);
We’re peeking ahead a bit here. In Programming Bitcoin we don’t start seeing these huge numbers until the chapter on Elliptic Curve Cryptography but I’ve mentioned this here because I’ll use the BigInteger type everywhere right from the start so I don’t have to change everything later.
« Previous: Big Numbers Are Big
Next: Finite Fields in C# »
Series: BTC# – Learning to Program Bitcoin in C#
« Previous: Modular Arithmetic
Next: Big Integers in C# »
The private keys we use to secure our funds or our communications are 256-bit numbers chosen at random and then kept secret. What happens if two people randomly choose the same number? Or if you guess someone else’s number?
That’s very bad. If you somehow get hold of someone else’s secret number, you have the keys to their funds.
How likely is that to happen?
Vastly hugely mindbogglingly unlikely.
A 256-bit key has 2256 possible values. Expanded into its decimal format that’s 1.15 x 1077. 115,792,089,237,316,195,423,570,985,008,687,907,853,269,984,664,640,564,039,457,584,007,913,129,639,939. 115 quattuorvigintillion. A number so big you’ve never even heard the word before.
Roughly the number of atoms in the universe.

At the end of Chapter One of Applied Cryptography, Bruce Schneier provides a table of large numbers. He lists things like the odds of being killed by lightning (1 in 9 billion per day) and the odds of winning a state lottery (1 in 4 million), which we can compare to the odds of randomly selecting two identical 256-bit private keys.
The odds of getting killed by lightning the day you win the lottery are 1 in
9 x 109 x 4 x 106 = 3.6 x 1016
i.e. 1 in 36 million billion, 36 with 15 zeroes after it, which doesn’t even touch the sides of crypto-maths-sized numbers. We’re still gonna need some bigger numbers to multiply by if we want to get close.
Now imagine that instead of guessing the numbered balls that will tumble out of the Powerball machine that you have a much bigger machine tumbling the entire Sahara Desert and you have to guess which grain of sand will come out. There are 1.5 x 1024 grains of sand in the Sahara Desert, according to BBC Earth.
The odds of you winning this Sahara lottery, correctly guessing which grain of sand will pop out of the machine and simultaneously getting struck by lighting are 1 in.
9 x 109 x 1.5 x 1024 = 1.35 x 1034
If the Sahara lottery was just the qualifying round and to win you had to then do the same thing but pick the correct grain of sand from the Gobi desert the odds would be 1 in
9 x 109 x 1.5 x 1024 x 1 x 1023 = 1.35 x 1057
which is still only one hundred-quintillionth of 115 quattuorvigintillion but I’ll stop here because it’s getting silly.

The chance of a random collision of 2 256-bit numbers is a hundred quintillion times lower than the odds of the ridiculous Sahara-lightning-lottery thing. It’s not gonna happen.
« Previous: Modular Arithmetic
Next: Big Integers in C# »
Series: BTC# – Learning to Program Bitcoin in C#
« Previous: Start at the Very Beginning
Next: Big Numbers Are Big »
It was a bright cold day in April, and the clocks were striking thirteen.
Clocks striking thirteen signify a world gone mad. The opening line of George Orwell’s 1984 is unsettling because in the familiar world, clocks have circular faces; they go round to twelve and then loop back to one again.

